
With the rise of locally run LLMs, I set out to explore the performance of DeepSeek R1, a powerful open-weight model, across different hardware setups in my homelab. I tested the 1.5B, 7B, and 14B variants to evaluate their speed, memory efficiency, and overall usability. My goal was to determine the best balance between performance and practicality for local inference, comparing Apple Silicon (M1 & M4) with a Windows PC powered by an RTX 3080. The results were both insightful and unexpected, highlighting just how much hardware impacts real-world LLM performance.
For consistency, I used the same prompt across all tests:
👉 “Teach me Python Step by Step.”
Hardware Configurations
I tested DeepSeek R1 models on the following hardware:
- Mac Mini M1 (8GB RAM) – Apple’s first-generation M-series chip.
- Mac Mini M4 (16GB RAM) – The latest Apple Silicon iteration.
- Windows PC with NVIDIA RTX 3080 (10GB VRAM) – A high-performance consumer GPU.
DeepSeek R1 Model Performance Breakdown
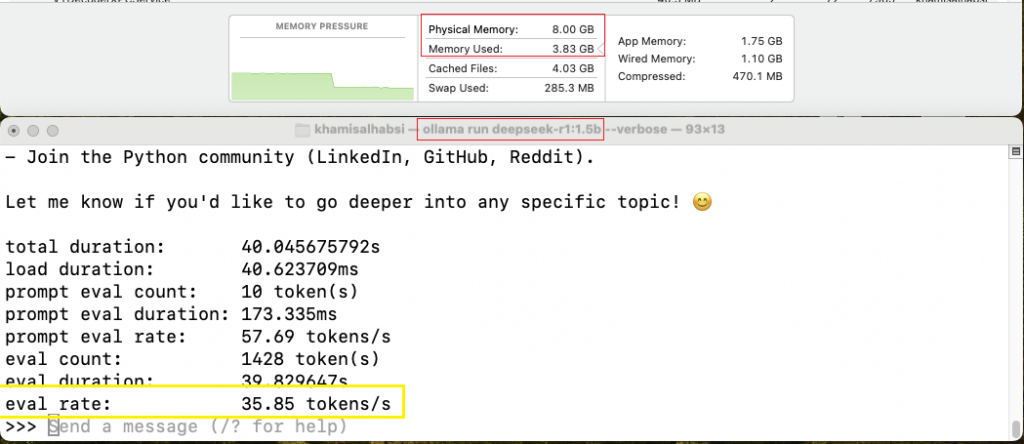
1️⃣ Mac Mini M1 (8GB RAM)
The M1 chip, despite its age, remains surprisingly capable. However, running larger models on an 8GB RAM machine has limitations.
🔹 1.5B Model:
- ✅ Token Generation Speed: ~35 tokens/sec
- ✅ Memory Usage: ~4GB
- ✅ Usability: Smooth experience with minimal slowdowns
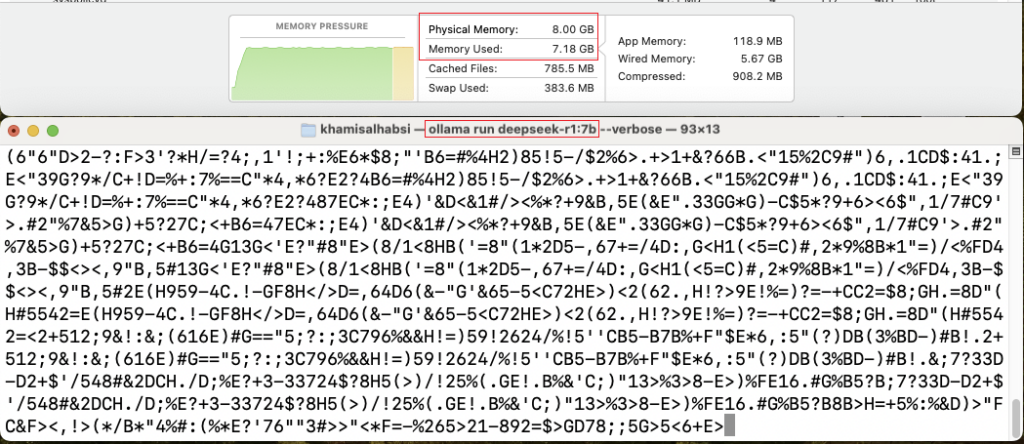
🔹 7B Model:
During testing, the model exhibited strange behaviour, responding with unknown symbols infinitely instead of producing coherent text. This issue was not observed in other hardware setups, suggesting potential incompatibility or inefficiency in running the 7B model on M1.
- ⚠ Token Generation Speed: ~[unknown] tokens/sec
- ⚠ Memory Usage: Swaps heavily due to limited RAM
- ❌ Usability: Frequent slowdowns and lag
🔹 14B Model:
- ❌ Not feasible due to extreme memory constraints
💡 Verdict: The M1 is suitable only for smaller models like 1.5B ~ 3B Max. Running anything larger leads to slow inference and excessive memory swapping.
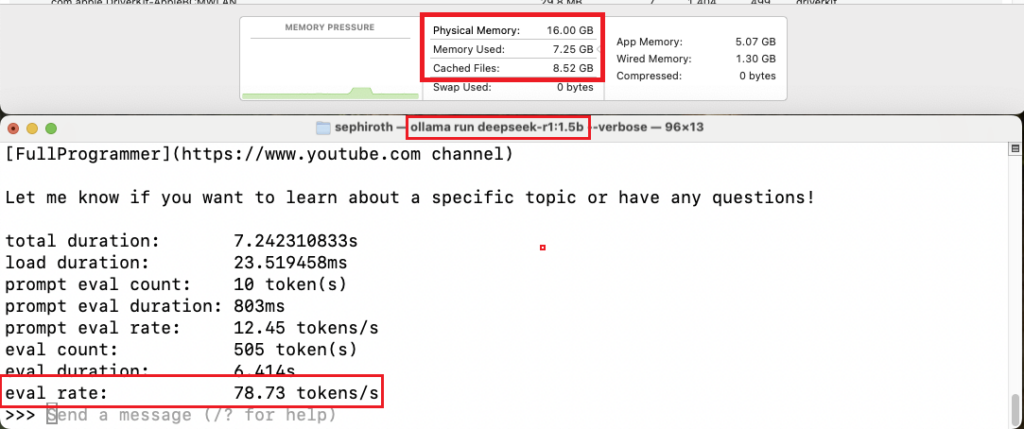
2️⃣ Mac Mini M4 (16GB RAM)
With improved GPU and memory bandwidth, the M4 chip handles larger models better than the M1.
🔹 1.5B Model:
- ✅ Token Generation Speed: ~80 tokens/sec
- ✅ Memory Usage: ~6.5GB
- ✅ Usability: Very smooth
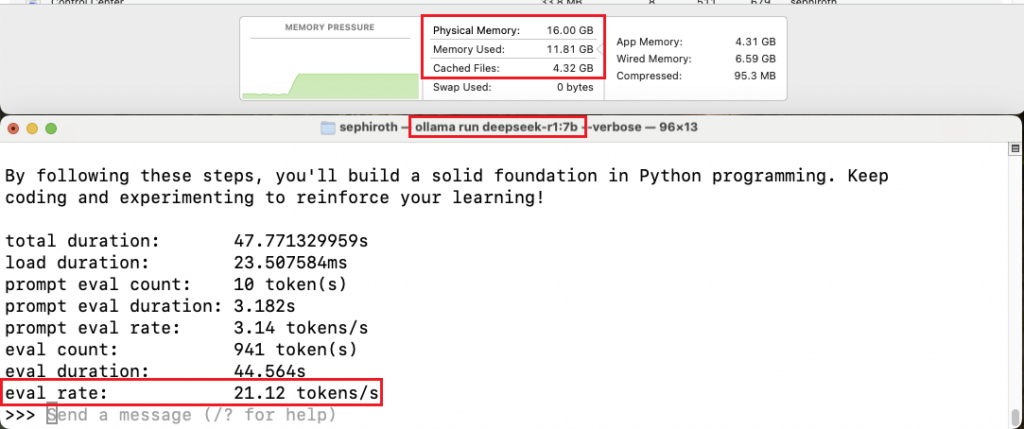
🔹 7B Model:
- ✅ Token Generation Speed: ~22 tokens/sec
- ✅ Memory Usage: ~12GB
- ✅ Usability: Usable, but the system may slow down under load
🔹 14B Model:
- ⚠ Token Generation Speed: ~10 tokens/sec
- ❌ Memory Usage: Exceeds available RAM, leading to heavy swapping
- ❌ Usability: Not practical for local inference
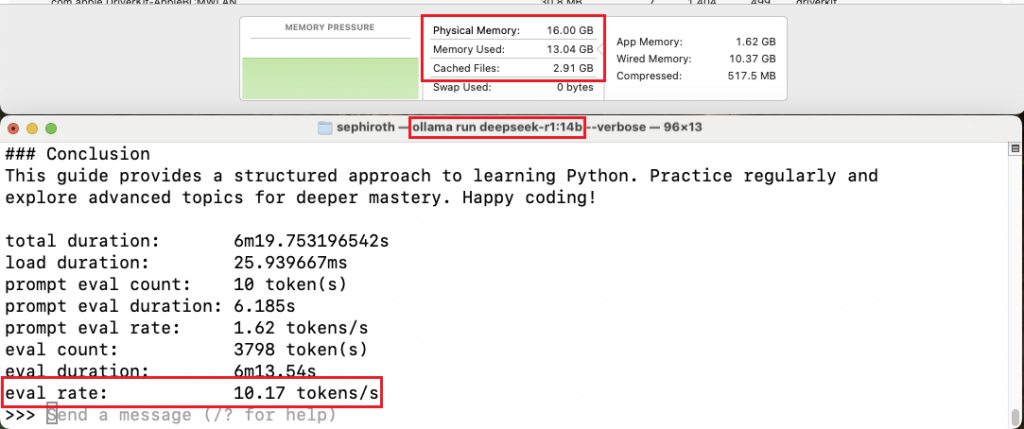
💡 Verdict: The M4 significantly outperforms the M1. It comfortably handles 7 B but struggles with 14B, making it best suited for medium-sized models.
3️⃣ Windows PC (RTX 3080, 10GB VRAM)
GPUs are typically the best for AI workloads, and the RTX 3080 was no exception.
🔹 1.5B Model:
- ✅ Token Generation Speed: ~120 tokens/sec
- ✅ Memory Usage: ~3GB VRAM
- ✅ Usability: Extremely smooth
🔹 7B Model:
- ✅ Token Generation Speed: ~54 tokens/sec
- ✅ Memory Usage: ~6GB VRAM
- ✅ Usability: Runs flawlessly
🔹 14B Model:
- ⚠ Token Generation Speed: ~18 tokens/sec
- ⚠ Memory Usage: Nearly maxes out VRAM
- ⚠ Usability: Works, but some lag is noticeable
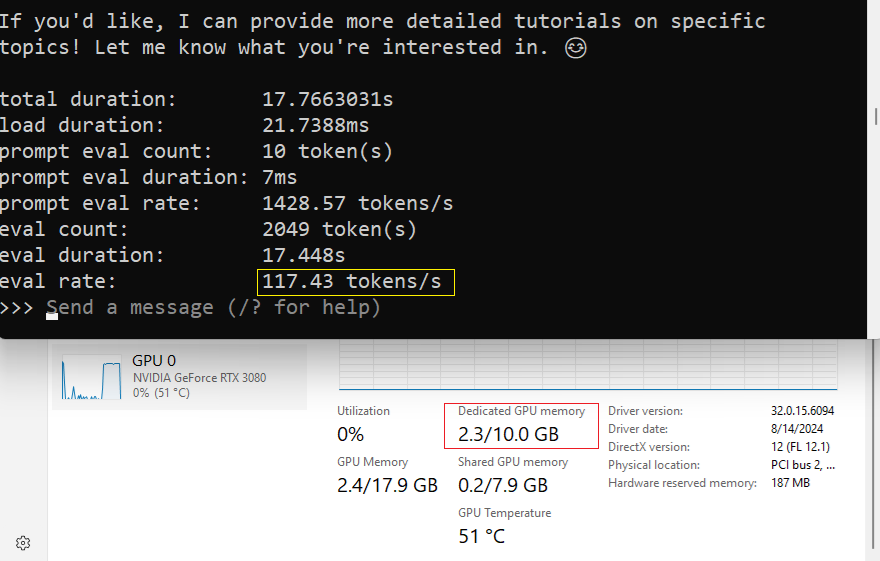
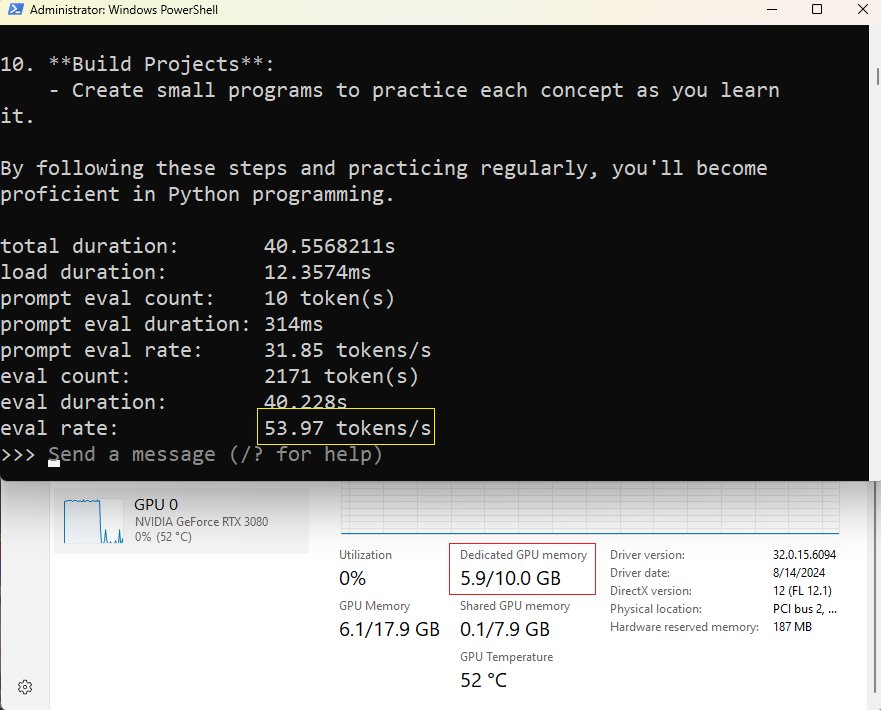

💡 Verdict: The RTX 3080 dominates in performance, making even 14B feasible. However, 10GB VRAM is limiting for larger models.
Conclusion: Best Setup for Local DeepSeek R1 Inference
| Hardware | 1.5B Performance | 7B Performance | 14B Performance | Overall Verdict |
|---|---|---|---|---|
| Mac Mini M1 (8GB) | ✅ Smooth | ❌ Struggles | ❌ Not possible | Only good for 1.5B |
| Mac Mini M4 (16GB) | ✅ Smooth | ✅ Usable | ❌ Too slow | Best for 1.5B & 7B |
| RTX 3080 (10GB VRAM) | ✅ Fastest | ✅ Excellent | ⚠ Feasible but VRAM limited | Best overall for local inference |
Final Thoughts
I really enjoyed experimenting with DeepSeek LLM in my homelab across different hardware—M1, M4, and RTX 3080. It was fascinating to see how the same model behaved differently depending on the setup. The RTX 3080 provided the smoothest and most stable experience, while the M4 showed impressive efficiency in handling larger models. The M1, though surprisingly capable, had some quirks—especially with the 7B model, which got stuck in an infinite loop of unknown symbols.
This whole process reinforced my belief that hardware choice directly impacts LLM performance, stability, and overall usability. It’s not just about raw power—different setups introduce unique challenges and surprises.
Overall, this was a fun and insightful experiment. DeepSeek LLM is a solid model, but the right hardware setup can make all the difference. I’m looking forward to more experiments and pushing the limits even further in my homelab! 🚀
I set up a demo for you to try—check it out at https://chat.habsi.net! 🚀

Post Comment